众数 发表评论(0) 编辑词条
众数(Mode)
什么是众数 编辑本段回目录
众数是指一组数据中出现次数最多的那个数据,一组数据可以有多个众数,也可以没有众数。众数是由英国统计学家皮尔生首先提出来的。所谓众数是指社会经济现象中最普遍出现的标志值。从分布角度看,众数是具有明显集中趋势的数值。
例如:某制鞋厂要了解消费者最需要哪种型号的男皮鞋,调查了某百货商场某季度男皮鞋的销售情况,得到资料如下表(某商场某季度男皮鞋销售情况):
| 男皮鞋号码/厘米 | 销售量/双 |
|---|---|
| 24.0 | 12 |
| 24.5 | 84 |
| 25.0 | 118 |
| 25.5 | 541 |
| 26.0 | 320 |
| 26.5 | 104 |
| 27.0 | 52 |
| 合计 | 1200 |
从表中可以看到,25.5厘米的鞋号销售量最多,如果我们计算算术平均数,则平均号码为25.65厘米,而这个号码显然是没有实际意义的,而直接用25.5厘米作为顾客对男皮鞋所需尺寸的集中趋势既便捷又符合实际。
统计上把这种在一组数据中出现次数最多的变量值叫做众数。用Mo表示。它主要用于定类(品质标志)数据的集中趋势,当然也适用于作为定序(品质标志)数据以及定距和定比(数量标志)数据集中趋势的测度值。上面的例子中,鞋号25.5厘米就是众数。
众数的计算 编辑本段回目录
由品质数列和单项式变量数列确定众数比较容易,哪个变量值出现的次数最多,它就是众数,如上面的两个例子。
若所掌握的资料是组距式数列,则只能按一定的方法来推算众数的近似值。计算公式为:
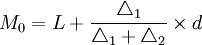
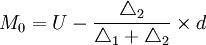
式中:
- L——众数所在组下限;
- U——众数所在组上限;
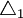 ——众数所在组次数与其下限的邻组次数之差;
——众数所在组次数与其下限的邻组次数之差;
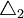 ——众数所在组次数与其上限的邻组次数之差;
——众数所在组次数与其上限的邻组次数之差;
- d——众数所在组组距。
例:根据下表的数据,计算50名工人日加工零件数的众数。

解:从表中的数据可以看出,最大的频数值是14,即众数组为120~125这一组,根据公式得50名工人日加工零件的众数为:
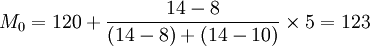 (件)
(件)
或: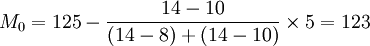 (件)
(件)
众数是一种位置平均数,是总体中出现次数最多的变量值,因而在实际工作中有时有它特殊的用途。诸如,要说明一个企业中工人最普遍的技术等级,说明消费者需要的内衣、鞋袜、帽子等最普遍的号码,说明农贸市场上某种农副产品最普遍的成交价格等,都需要利用众数。但是必须注意,从分布的角度看,众数是具有明显集中趋势点的数值,一组数据分布的最高峰点所对应的数值即为众数。当然,如果数据的分布没有明显的集中趋势或最高峰点,众数也可能不存在;如果有两个最高峰点,也可以有两个众数。只有在总体单位比较多,而且又明显地集中于某个变量值时,计算众数才有意义。
众数的特点 编辑本段回目录
1、众数是以它在所有标志值中所处的位置确定的全体单位标志值的代表值,它不受分布数列的极大或极小值的影响,从而增强了众数对分布数列的代表性。
2、当分组数列没有任何一组的次数占多数,也即分布数列中没有明显的集中趋势,而是近似于均匀分布时,则该次数分配数列无众数。若将无众数的分布数列重新分组或各组频数依序合并,又会使分配数列再现出明显的集中趋势。
3、如果与众数组相比邻的上下两组的次数相等,则众数组的组中值就是众数值;如果与众数组比邻的上一组的次数较多,而下一组的次数较少,则众数在众数组内会偏向该组下限;如果与众数组比邻的上一组的次数较少,而下一组的次数较多,则众数在众数组内会偏向该组上限。
4、缺乏敏感性。这是由于众数的计算只利用了众数组的数据信息,不象数值平均数那样利用了全部数据信息。
附件列表
→如果您认为本词条还有待完善,请 编辑词条
词条内容仅供参考,如果您需要解决具体问题
(尤其在法律、医学等领域),建议您咨询相关领域专业人士。
0
标签: 众数 品质数列 总体 成交价格 次数 消费者 消费者需要 百货商场 算术平均数 统计

同义词: 暂无同义词
关于本词条的评论 (共0条)发表评论>>

