统计推断 发表评论(0) 编辑词条
统计推断(Statistical Inference)
什么是统计推断 编辑本段回目录
统计在研究现象的总体数量关系时,需要了解的总体对象的范围往往是很大的,有时甚至是无限的,而由于经费、时间和精力等各种原因,以致有时在客观上只能从中观察部分单位或有限单位进行计算和分析,根据局部观察结果来推断总体。例如,要说明一批灯泡的平均使用寿命,只能从该批灯泡中抽取一小部分进行检验,推断这一批灯泡的平均使用寿命,并给出这种推断的置信程度。这种在一定置信程度下,根据样本资料的特征,对总体的特征做出估计和预测的方法称为统计推断法。统计推断是现代统计学的基本方法,在统计研究中得到了极为广泛的应用,它既可以用于对总体参数的估计,也可以用作对总体某些分布特征的假设检验。
统计推断是在概率论的基础上依据样本的有关数据和信息,对未知总体的质量特性参数,做出合理的判断和估计。它的一般过程如图l所示。
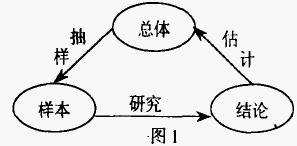
统计推断有着广泛的用途,几乎遍及所有科学技术领域,在质量管理活动中应用尤其普遍。因此,讨论统计推断是一个十分有意义的课题。
统计推断的必要性 编辑本段回目录
为什么我们不能直接研究对象的全部情况,而只能取得研究对象的部分信息来推断和估计整体的某些规律呢?
1、在产品可靠性T程领域,研究某种产品在规定条件下和规定时间内完成规定功能的概率时,通常要做破坏性检验和试验,如灯泡的寿命测试、焊缝的强度检验、电视机无故障工作时间的确定等。我们只能通过抽取样本,对样本进行破坏性试验后,推断总体的可靠性指标。如果对所有产品进行破坏性检测,就没有产品可供销售了,这违背了我们研究的本来目的。
2、还有一些研究对象,组成其整体的个体是无限多的,客观上对全部个体进行观察和检验是根本不可能的。如研究海水中微生物的情况时,不可能将全部海水都装入试管中;分析鱼池中全部活鱼的重量与长度时,不能将池水抽干、逐条过秤等。因此,只能用随机取样统计推断的方法。
3、有些情况对全部个体逐一研究、检测是可以的,但需要付出非常多的财力、物力和时间。如自动化流水作业的生产过程,对每个产品进行检测需要停机等。因此,我们也只能依赖于抽样检验和调查,分析样本后对整体做出判断。
4、由于整体的不均匀性和样本的随机性,利用分析样本得到的数据来推断总体的情况必然会产生偏差。但是,在大多数情况下这种估计误差的存在是合理的,也是可以容忍的。因为不同的问题有不同的精度要求,并不是所有问题都需要一个绝对准确的估量,也不是一切问题都能得到一个非常精确的结果,所以统计推断是不可缺少的研究手段。
统计推断的基本方法 编辑本段回目录
在质量活动和管理实践中,人们关心的是特定产品的质量水平,如产品质量特性的平均值、不合格品率等。这些都需要从总体中抽取样本,通过对样本观察值分析来估计和推断,即根据样本来推断总体分布的未知参数,称为参数估计。参数估计有两种基本形式:点估计和区间估计。
1、点估计
用样本的统计量去估计总体相应未知参数称为点估计。当我们任意抽取一个样本:x1、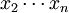 ,该样本的均值E(x)和方差D(X)便已知:
,该样本的均值E(x)和方差D(X)便已知:
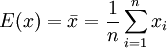
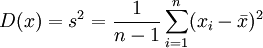
如果已知该样本所属总体的分布犁式,则可利用总体分布型式均值和方差的计算公式推断其分布的未知参数。如表l所示。
| 二项分布B(N,P) | 泊松分布P(λ) | 均匀分布U(a,b) | 正态分布N(μ,σ2) |
|---|---|---|---|
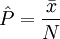 | 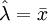 | 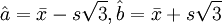 | 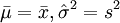
|
对于同一总体,随着抽取样本的不同,就可得到不同的样本均值和方差,通过计算.同一总体分布未知参数就可产生多个估计值。这样,就存在对众多点估计优良性的评价问题。通常用无偏性和有效性作为评价点估计优良性的标准。即如果所有估计量的均值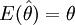 ,称这些估计量
,称这些估计量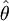 为参数θ的无偏估计,在多个无偏估计量中方差小的估计量则更为有效。
为参数θ的无偏估计,在多个无偏估计量中方差小的估计量则更为有效。
2、区间估计
用样本确定两个统计量,构筑一个置信水平为1 − α的区间,对总体未知参数给出估计,称为区间估计。如果从正态总体中抽取一个样本:x1、,其样本的均值为:
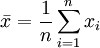
方差为:
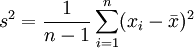
则该正态总体均值、方差和标准差的1 − α置信估计区间如表2所示。

点估计仅仅给出未知参数的一个具体估计值,没有给出估计的精度,而区间估计却体现了估计的精度。所谓置信水平1 − α,是指所构造的置信区间覆盖未知参数的概率为1 − α。由于置信区间是由选用样本的统计量构筑的,它是会随着样本的变化而变化的,它有时覆盖未知参数,有时却没有覆盖未知参数。但是,用此法构筑的置信区间,在100次中大约有100(1 − α)个区间覆盖未知参数。
统计推断的两类错误 编辑本段回目录
人们总是希望不犯错误,但是在统计推断过程中不犯错误是不可能的。由于总体的不均匀性和样本的随机性,统计推断必然存在风险(错误)。假设有一批未知质量状况的产品,现在随机抽取其中的一个样本,通过检验、分析样本的质量状况,来推断整批产品的质量好坏,则可能出现如表3所示的四种情况。
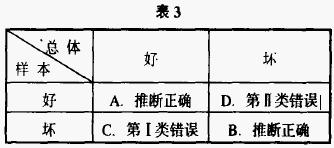
A、假定这批产品质量是好的,通过检验样本发现样本质量也是好的,则推断该批产品质量好而决定接收。显然,这个统计推断是完全正确的。B、假定这批产品质量不好,通过检验发现样本质量不好,则推断该批产品质量不好而拒收。该统计推断结论也是合理的。C、如果该批产品质量是好的,而通过检验样本发现样本质量是坏的,则推断该批产品质量不好而拒收,就犯了“弃真”的错误,习惯上把它称做第Ⅰ类错误。D、如果该批产品质量不好,通过检验样本发现样本质量是好的,则推断该批产品质量好而予以接收,则犯了“取伪”的错误,通常将其称做第Ⅱ类错误。
犯错误就会造成损失,就会发生预测失误、判断失误,就会导致不希望结果的发生。在统计推断过程中上述两类错误总是此涨彼消不可避免的,我们的原则是控制两类错误带来的损失最小且已知。
在不同的统计推断过程中,对上述两类错误有着不同的描述。在用控制图进行统计过程控制中,第Ⅰ类错误叫“虚发警报”,即生产正常而点子偶然超出控制界限,依此就判异而犯“弃真”错误;第Ⅱ类错误叫“漏发警报”,即过程已经异常,有部分点子仍位于控制界限内。依此判过程正常而犯“取伪”错误。在抽样检验过程中,第Ⅰ类错误为生产方风险,即对于给定的抽样方案,当质量水平为某一指定的可接收质量时被拒收的概率,此时生产方遭受损失;第Ⅱ类错误为使用方风险,即对于给定的抽样方案,当质量水平为某一指定的不满意质量时被接收的概率,此时使用方承受损失。在假设检验过程中,犯两类错误的情况如表4。
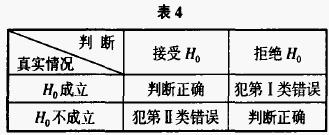
当原假设H0成立时,由于样本观察值落人拒绝域W中而误认为H0不成立,犯“弃真”错误;当原假设H0实际上不成立,由于样本观察值未落人拒绝域W而误认为H0成立,犯“取伪”错误。
统计推断提高准确性的途径 编辑本段回目录
个体是总体的一部分,局部的特性能反映全局的特点,但是,由于总体的不均匀性和样本的随机性,又使得样本不能精确地反映总体。因此,抽取部分个体经分析得出有关总体的结论存在着差错和不可靠。从理论上讲有两种途径可以消除和减少这种差错。其一,使总体最大限度地均匀。总体是我们要研究的未知事物,我们往往不可能改变他的均匀性,当能够使其达到理想的均匀时,已经完全掌握了它,没有研究的必要了。其二,采取适当的抽样方法确保抽样的“代表性”,可有效地控制和提高统计推断的可靠性和正确性。
随机抽样的方法很多,常用的有:
1、简单随机抽样
简单随机抽样,是指抽样过程应独立进行并且总体中每个个体被抽到的机会均等。随机抽样不是随便抽取,随便抽取容易受到个人好恶的影响。为实现随机化,可采取抽签、掷随机数骰子或查随机数值表等办法。如从100件产品中随机抽取l0件组成样本,可以把这100件产品从l开始编号直到100号,然后用抓阄的办法任意抽出l0个编号,由这l0个编号代表的产品组成样本。此种抽样方法的优点是抽样误差小,缺点是手续繁杂。在实践中真正做到每个个体被抽到的机会相等是不容易的。
2、周期系统抽样
周期系统抽样,又叫等距抽样或机械抽样,即将总体按顺序编号,用抽签或查随机数值表的方法确定首件,进而按等距原则依次抽取样本。如从120个零件中取五个做样本,先按生产顺序给产品编号,用简单随机抽样法确定首件,然后按每隔24(由120÷5=24得)个号码抽取一个,共抽取五个组成样本。这种方法特别适用于流水线上取样,操作简便,实施起来不易出现差错。但抽样起点一经确定,整个样本就完全固定。对总体质量特性含有某种周期性变化,而当抽样间隔恰好与质量特性变化周期吻合时,就可能得到一个偏差很大的样本。
3、分层抽样法
分层抽样法,即从一个可以分成不同子总体的总体中,按规定比例从不同层中随机抽取个体的方法。当不同设备、不同环境生产同一种产品时,由于条件差别产品质量可能有较大差异,为了使所抽取的样本具有代表性,可以将不同条件下生产的产品组成组,使同一组内产品质量均匀,然后在各组内按比例随机抽取样品合成一个样本。这种抽样方法得到的样本代表性比较好,抽样误差较小,缺点是抽样手续较繁,常用于产品质量检验。
4、整群抽样法
这种方法是先将总体按一定方式分成多个群,然后随机地抽取若干群并由这些群中的所有个体组成样本。如按照生产过程将1000个零件分别装入2O个箱中,每箱5O个,然后随机抽取一箱,此箱中5O个零件组成样本。这种抽样方法实施方便,但样本来自个别群体而不能均匀分布在总体中,因而代表性差,抽样误差较大。
附件列表
→如果您认为本词条还有待完善,请 编辑词条
词条内容仅供参考,如果您需要解决具体问题
(尤其在法律、医学等领域),建议您咨询相关领域专业人士。
0
标签: 统计推断 产品 产品质量 假设检验 分层抽样法 区间估计 可靠性 周期系统抽样 在产品 总体 总体参数

同义词: 暂无同义词
关于本词条的评论 (共0条)发表评论>>

